Database vs Data Lake vs Data Warehouse
Understanding the Basics
What is data? A data can be anything or everything that consists of any information or facts, in any form such as figures, text, image, even signals from any devices. A data can be Structured data and Unstructured data or sometimes semi-structured data. In this evolving world there are tons of data to be stored. Databases, data warehouses, and data lakes are the terms you need to know. This blog will break down the differences between these three data storage solutions in simple terms, helping you understand their unique roles, strengths, and use cases. By the end, you’ll have a clear idea of which one best suit your needs or how they can work together for smarter data management.
What is Database?
Database is a container fill with information and facts which is electronically stored in your pc’s. Any Kind of data can be stored in database the purpose to store the data into database so it can be easily accessed modified protected and analysed. For instance, a table that neatly organizes and stores client information (name, address, and phone number).
Evolution of Database
The evolution of databases showcases how data management has advanced over time. It began with flat file databases, where data was stored in plain text files without any structure. This evolved into hierarchical databases, organizing data in a tree-like structure, followed by network databases, which allowed more complex relationships through a graph-like structure. By 2020, the focus shifted to relational databases (like Oracle), where data is structured into tables with relationships, and non-relational databases (like MongoDB), designed for handling unstructured or semi-structured data, catering to modern applications and big data needs.
Why use Database?
If your application needs to store data (and nearly every interactive application does), your application needs a database. Applications across industries and use cases are built on databases. Here are some key reasons to use a database:
- Structured Data Storage: Databases help store information in an organized and systematic way, making it easy to retrieve and update.
- Data Security: They provide tools to protect sensitive information with permissions and encryption.
- Quick Access: Databases allow fast searching and retrieval of data, even when dealing with large amounts of information.
- Multi-User Access: Multiple users can access and work on the same data simultaneously without conflicts.
- Backup and Recovery: Built-in features allow easy backup and restoration in case of data loss.
Example of Databases
- Relational Databases (RDBMS): MySQL, Oracle, PostgreSQL, Microsoft SQL Server
- Non-Relational database: MongoDB, Cassandra and CouchDB
- Key-value database: Redis and DynamoDB
- Graph database: Neo4j and Amazon Neptune
- Wide-column stores: Cassandra and HBase
What is Data Lake?
A data lake is a centralized repository designed to store large volume of data at scale. A data lake can store structured, semi- structured and unstructured data. It allows you to store data as-it-is and process it later.
Unlike traditional databases or data warehouses that require data to be transformed and structured before storage, data lakes use a schema-on-read approach, meaning the data’s format is defined only when it’s accessed or analyzed. This flexibility makes data lakes ideal for big data analytics, machine learning, and advanced insights, as they retain all original data for future use.
Characteristics of Data Lake
Data lakes allow organizations to store diverse data types, including logs, videos, images, social media content, and more, which can be valuable for advanced analytics, machine learning, and big data processing.
Storing data in data lakes is much cheaper than in a data warehouse. Data lakes can store vast amounts of data at a lower cost, which is great for organizations looking to manage large datasets efficiently.
The flexible nature of data lakes enables business analysts and data scientists to look for unexpected patterns and insights. The raw nature of the data combined with its volume allows users to solve problems they may not have been aware of when they initially configured the data lake.
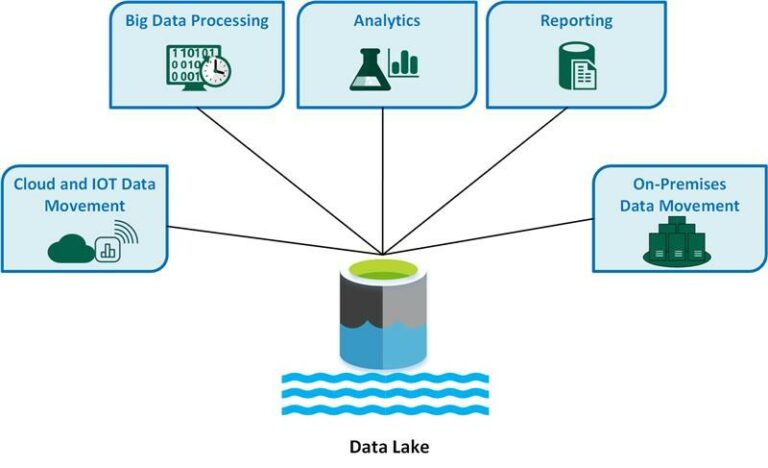
Example of Data Lake
- AWS S3: Widely used cloud-based data lake for storing vast amounts of raw data, integrated with other Azure services.
- Azure Data Lake Storage Gen2: A Microsoft solution designed for large-scale data storage and analytics
- Google Cloud Storage: A flexible and scalable data lake solution for unstructured and structured data, optimized for analytics on Google Cloud.
- AWS Athena: A powerful query engine that enables fast, scalable, and cost-effective analysis of data in Amazon S3-based data lakes.
- Databricks SQL Analytics: Provides a powerful interface to query and analyze data directly from data lakes using SQL, enabling real-time insights and advanced analytics.
Why use Data Lake?
Data lakes offer a cost-effective, flexible way to store diverse data in its raw form, enabling real-time analytics and insights.
- Cost-Effective Storage: It allows organizations to stores a huge amount of data at a lower cost compared to traditional data warehouses.
- Flexible Data Types: Can store all types unstructured, semi-structured and structured data. Unlike structured databases.
- Centralized Repository: Consolidate data from multiple sources and serves as a single, unified repository for all organizational data.
- Real-Time Processing: Enables faster decision-making for time-sensitive applications like fraud detection or operational monitoring and support real-time data ingestion and analytics.
- Integration with Analytics Tools: Integrate with analytics platforms like AWS Athena, Databricks, and Apache Spark, making it easier to extract insights without moving data between systems.
What is Data Warehouse?
Data warehouses are the system designed to store large amount of both current and historical data from various sources. The data warehouse is used to consolidate data from different sources for analysis, uncover insights, and generate business intelligence (BI) through reports and dashboards. A data warehouse is also referred as ‘data base’ but it’s not correct basically a data warehouse is the giant database used for analytics. Because of these features data warehouse is also known as the ‘single source of truth’.
Characteristics of Data Warehouse
A data warehouse collects data from many sources into a single centralized repository for analyse and easily access. Data warehouses are optimized to storing structured data, often organized in tables with predefined schemas.
Data warehouse is also time variant it enables the trend analyze and historical comparisons for improving the decisions making and scaling the business.
Extract, Transform, Load (ETL) process, is a process in which data is moved from various source systems to the data warehouse through the ensuring it is cleaned and organized.
Data warehouse integrate with business intelligence (BI) tools like Tableau and Power BI for creating reports and dashboards. It also optimized for fast querying and read operations. Data warehouses maintain data integrity and consistency, making them essential for data-driven decision-making and business analytics.
Morden data warehouse have evolved to supporting the semi structured data also.
Why use Data Warehouse?
If you are running a huge company and want to store large amount of historical data for example (names, files, sheets, product info) and analyze your data to generate business intelligence. Data warehouse is a very good option for you. Highly structured nature of data warehouse makes analysing data relatively straightforward and simple for business analyst and data scientists.
Examples of Data Warehouse
- Amazon Redshift: A cloud-based data warehouse by AWS, known for its scalability, speed, and seamless integration with other AWS services.
- Google BigQuerry: A serverless and highly scalable data warehouse from Google Cloud, ideal for real-time analytics on large datasets.
- IBM Db2 Warehouse: A cloud-based or on-premises solution for advanced analytics and machine learning integration.
- Microsoft Azure Synapse: A data warehouse and big data analytics platform from Microsoft Azure, enabling advanced analytics with integrated machine learning.
- Snowflake: A cloud-native data warehouse that supports structured and semi-structured data, offering flexibility and high performance.
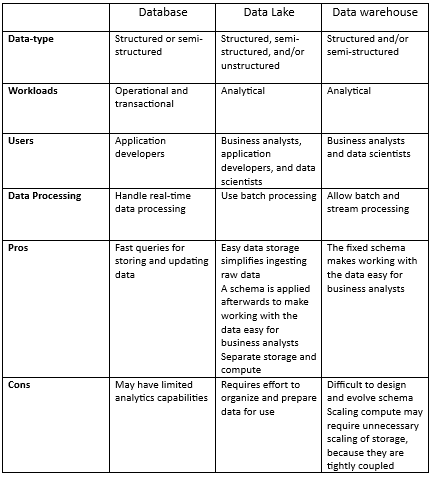
Key Differences
Databases, data warehouses, and data lakes are all used to store data. So, what’s the difference?
Let’s see the key difference between them:
Conclusion
You can choose either database or data warehouse and data lakes according to your own requirements. Each have their own purpose and specialty. To store the current application data every modern application will require a database. And to analyze the applications’ current and historical data the application organizations may choose data warehouse or data lake. According to your requirements and budget.